Data as the foundation of ecosystems
The mission is clear – Schibsted is creating a digital ecosystem to connect data from different platforms and companies. But how does it really work? Adam Kinney, Head of Schibsted Data Science, guides us through four steps you need to take to fully realize the potential of data in an ecosystem.
There’s no doubt that data is hot. More and more businesses are asking their users to log in to share their information. With knowledge of your user and their behaviors, you can create personalized products and experiences that will be more relevant and create greater engagement and user growth. And in the end increase revenues.
In an ecosystem with several companies tied together you are able to get facts from different kinds of sites and platforms. Of course that means a bigger amount of data from more users, but it also means a larger variety of data that can provide an even bigger picture. If, for example, a user visits both a news site and a classified site, that will tell different things about him or her.
There are some basic sources of data you can work with in data analytics and in an ecosystem.
- Logged in user profiles.
- Events – whatever a user does within a site.
- Content – by analyzing what kind of content the user is consuming you can learn even more. For this the data science team uses language processing techniques, automatic tagging, and topic extractions.
- Global data views – how users are flowing around in the ecosystem and how growth is going across the entire system.
The data science team then uses the data to build data products. These are tools to create personalized products and services. One example is targeted ads – showing different ads to different persons based on their profiles. It could also mean giving readers content we know they are interested in, or offering services connected to a purchase we know the user intend to make. Better personalization, in turn, can increase the reach, frequency, and variety of an ecosystem. It is in this way that an ecosystem becomes a self-reinforcing growth engine.
To get to a fully realized data ecosystem there are a few steps, or stages of evolution, that you have to take. This is how Adam Kinney explains it:
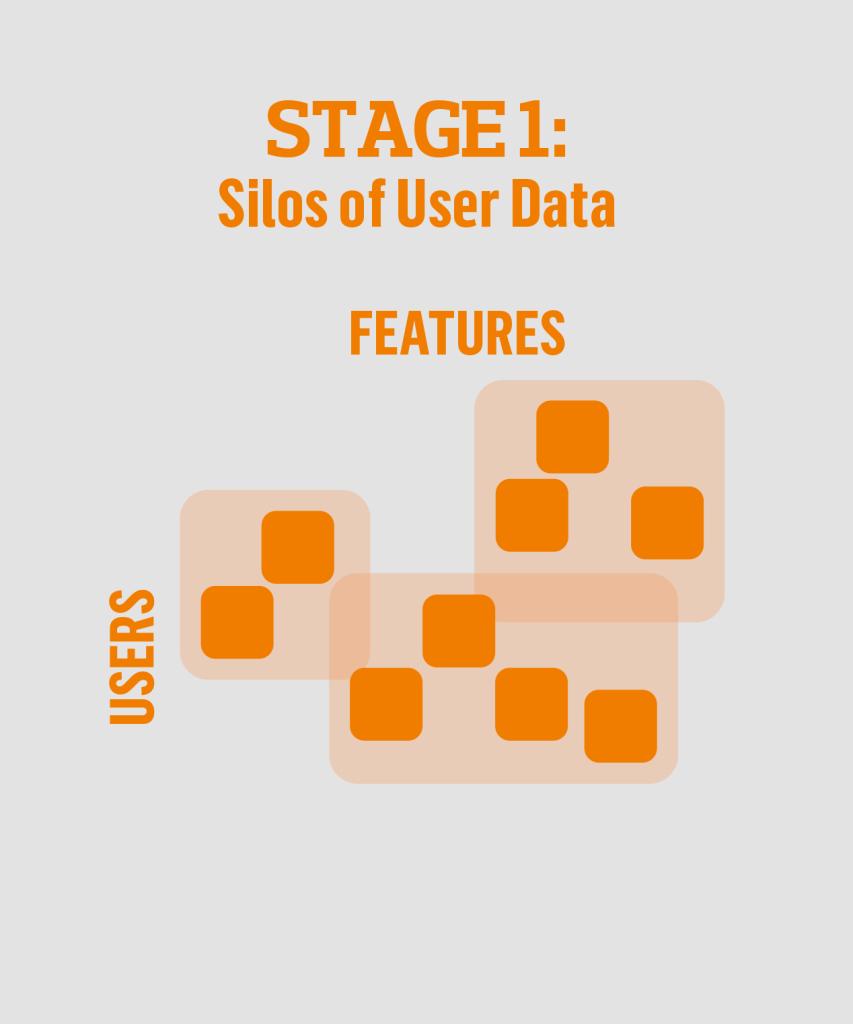
Stage 1: Silos of user data
This is where a lot of current ecosystems are now. Each of these orange blocks is one fact that we know about a user. We might know that a particular logged in user is 35 years old. Another user, visiting the classified site Finn, has used the car vertical five times last week. The boxes represent different companies and that each company builds its own understanding of users, independent of what is known about the same user of another Schibsted company.
At this stage the data exists, but a lot of the potential for using it comes by combining it.

Stage 2: Sums of user data
At this stage we have a common identification of both logged in and logged out users, which allows us to combine data. All significant actions that users take on any of the products in the ecosystem are collected in a central data store. If we visualize this as a matrix where you have users as rows, and features (facts about users) as columns, in this stage you get blanks, simply because we only have some facts.
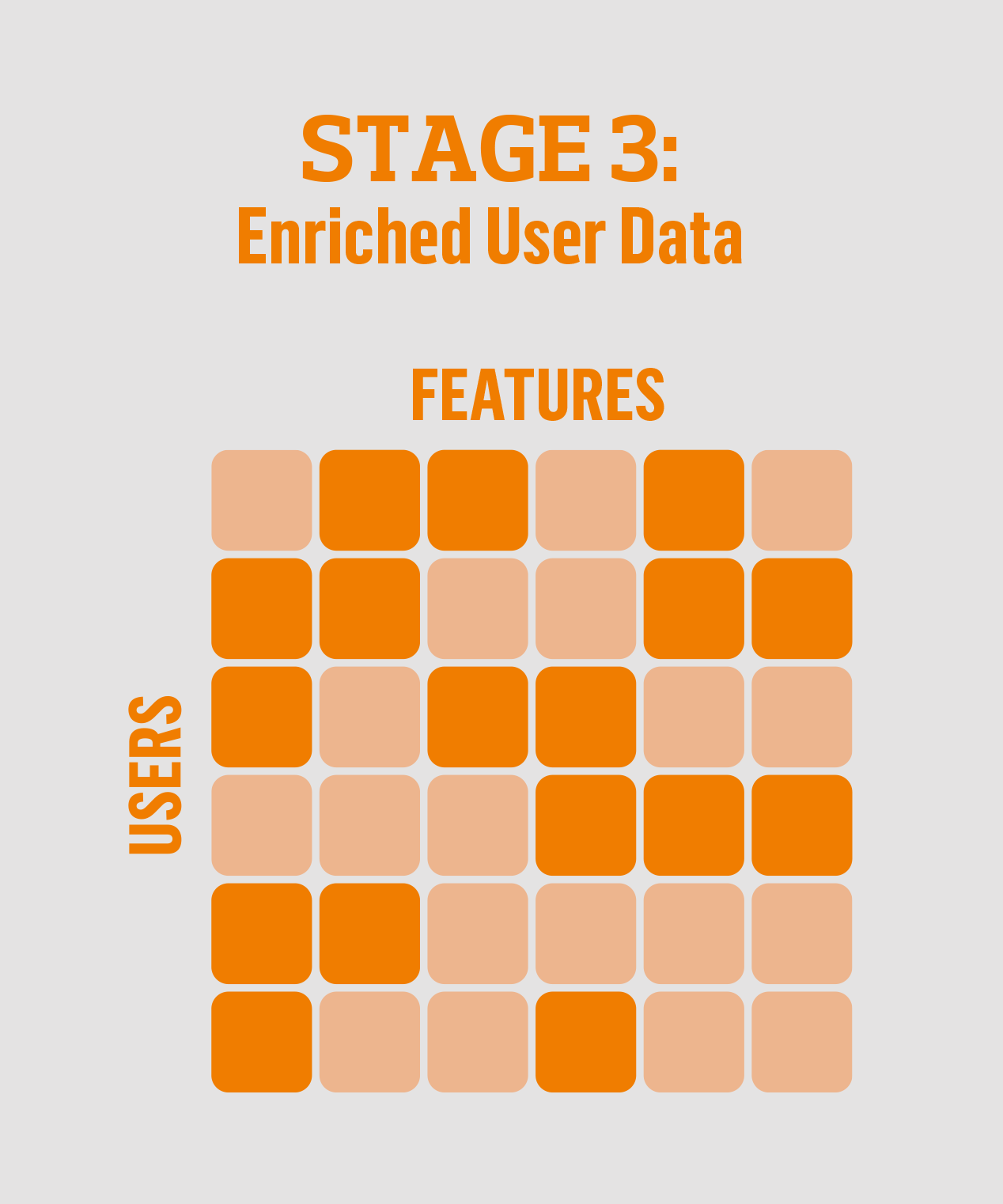
Stage 3: Enriched user data
Stage two is where we systematically start to fill in all the blank spots. We have enough data on different kinds of users to be able to predict the true values in the gaps to provide complete profiles on nearly all users. We use machine learning techniques and build what we call classifiers to predict these values. And we get what we call enriched data. As an example we’ve built a model for gender prediction. By identifying which categories logged in users at Finn, who have given us their gender, click on – we can now predict gender for 85 per cent of all users.
When we have filled this in sufficiently it enables the next generation of personalization.
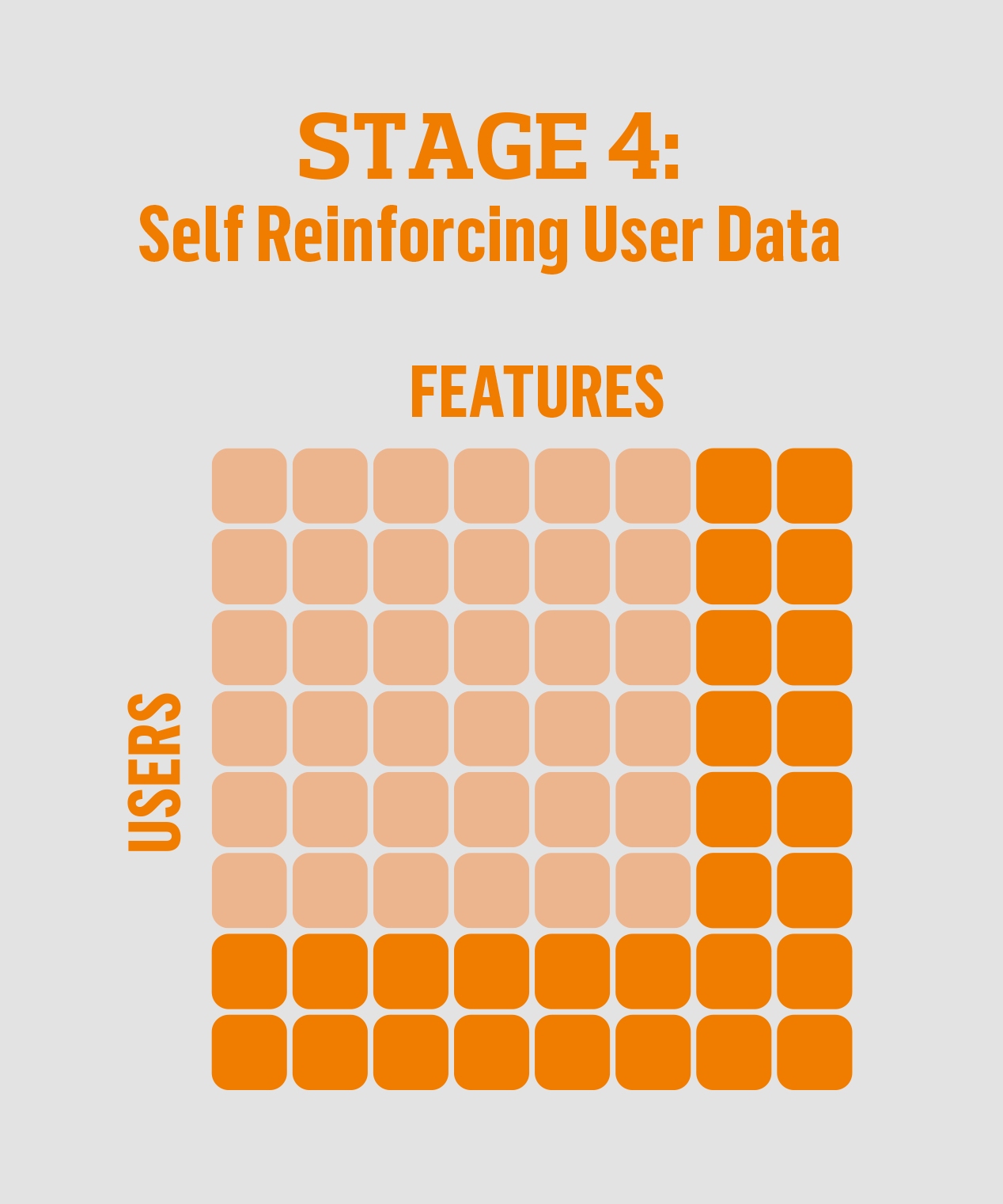
Stage 4: Reinforcing user data
This gets us to an ideal state, a selfreinforcing user data stage, where we’ve collected a sufficient critical mass of data that makes the process start taking on a life on its own.
New user patterns can be mined from the existing data, which then enable the accumulation of more user data, which can in turn be mined for more new patterns, and so on. At this point, new product innovations become possible in which we anticipate user needs and provide services to fulfill those needs.
And we can grow really, really big. This is the vision and Adam knows its power.
“I’ve seen, first hand, the power that enriched user data has to drive additional user growth – on top of what you’re going to get without it. That’s really impressive and powerful”, says Adam Kinney.